Hi HN! Smooth CLI (
https://www.smooth.sh) is a browser that agents like Claude Code can use to navigate the web reliably, quickly, and affordably. It lets agents specify tasks using natural language, hiding UI complexity, and allowing them to focus on higher-level intents to carry out complex web tasks. It can also use your IP address while running browsers in the cloud, which helps a lot with roadblocks like captchas (
https://docs.smooth.sh/features/use-my-ip).
Here’s a demo: https://www.youtube.com/watch?v=62jthcU705k Docs start at https://docs.smooth.sh.
Agents like Claude Code, etc are amazing but mostly restrained to the CLI, while a ton of valuable work needs a browser. This is a fundamental limitation to what these agents can do.
So far, attempts to add browsers to these agents (Claude’s built-in --chrome, Playwright MCP, agent-browser, etc.) all have interfaces that are unnatural for browsing. They expose hundreds of tools - e.g. click, type, select, etc - and the action space is too complex. (For an example, see the low-level details listed at https://github.com/vercel-labs/agent-browser). Also, they don’t handle the billion edge cases of the internet like iframes nested in iframes nested in shadow-doms and so on. The internet is super messy! Tools that rely on the accessibility tree, in particular, unfortunately do not work for a lot of websites.
We believe that these tools are at the wrong level of abstraction: they make the agent focus on UI details instead of the task to be accomplished.
Using a giant general-purpose model like Opus to click on buttons and fill out forms ends up being slow and expensive. The context window gets bogged down with details like clicks and keystrokes, and the model has to figure out how to do browser navigation each time. A smaller model in a system specifically designed for browsing can actually do this much better and at a fraction of the cost and latency.
Security matters too - probably more than people realize. When you run an agent on the web, you should treat it like an untrusted actor. It should access the web using a sandboxed machine and have minimal permissions by default. Virtual browsers are the perfect environment for that. There’s a good write up by Paul Kinlan that explains this very well (see https://aifoc.us/the-browser-is-the-sandbox and https://news.ycombinator.com/item?id=46762150). Browsers were built to interact with untrusted software safely. They’re an isolation boundary that already works.
Smooth CLI is a browser designed for agents based on what they’re good at. We expose a higher-level interface to let the agent think in terms of goals and tasks, not low-level details.
For example, instead of this:
click(x=342, y=128)
type("search query")
click(x=401, y=130)
scroll(down=500)
click(x=220, y=340)
...50 more steps
Your agent just says:
Search for flights from NYC to LA and find the cheapest option
Agents like Claude Code can use the Smooth CLI to extract hard-to-reach data, fill-in forms, download files, interact with dynamic content, handle authentication, vibe-test apps, and a lot more.
Smooth enables agents to launch as many browsers and tasks as they want, autonomously, and on-demand. If the agent is carrying out work on someone’s behalf, the agent’s browser presents itself to the web as a device on the user’s network. The need for this feature may diminish over time, but for now it’s a necessary primitive. To support this, Smooth offers a “self” proxy that creates a secure tunnel and routes all browser traffic through your machine’s IP address (https://docs.smooth.sh/features/use-my-ip). This is one of our favorite features because it makes the agent look like it’s running on your machine, while keeping all the benefits of running in the cloud.
We also take away as much security responsibility from the agent as possible. The agent should not be aware of authentication details or be responsible for handling malicious behavior such as prompt injections. While some security responsibility will always remain with the agent, the browser should minimize this burden as much as possible.
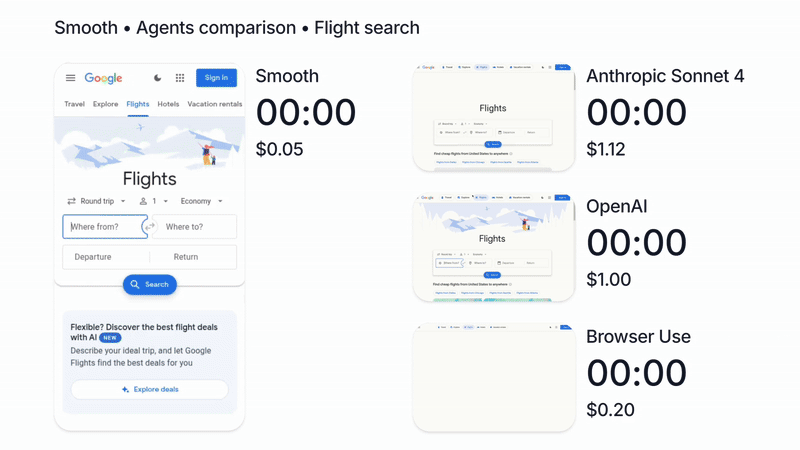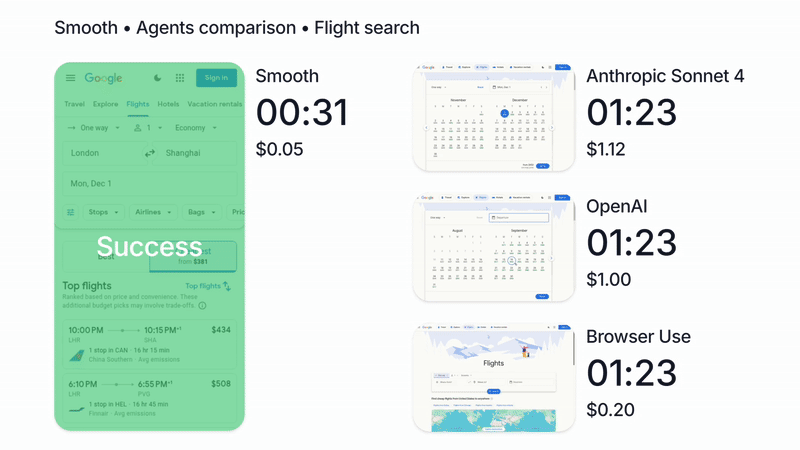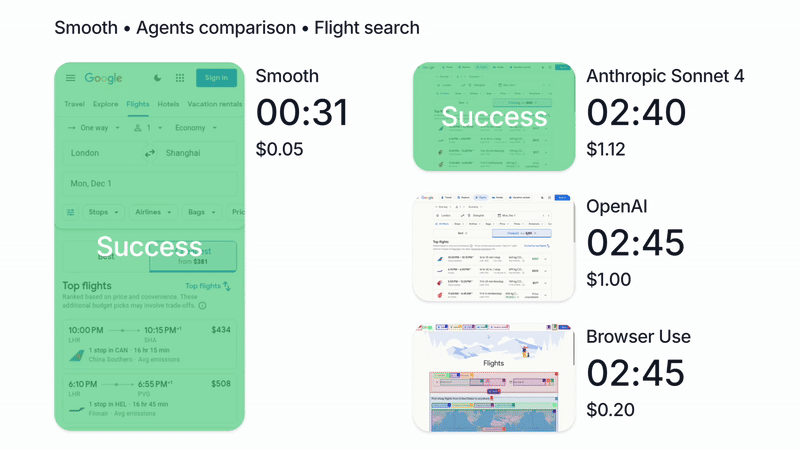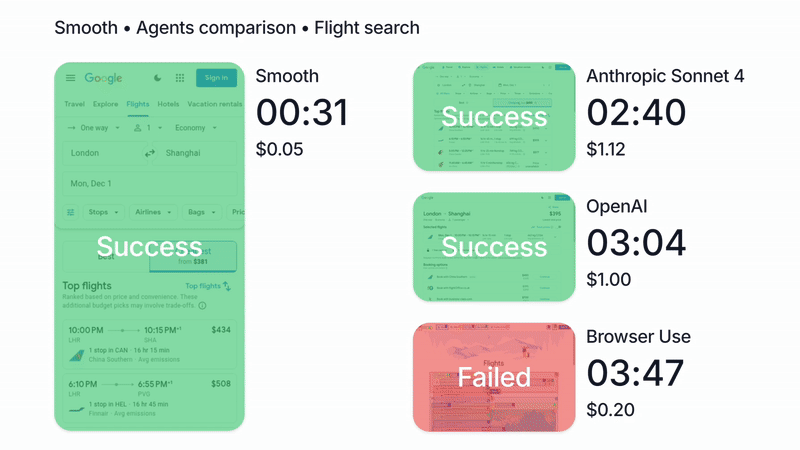
We’re biased of course, but in our tests, running Claude with Smooth CLI has been 20x faster and 5x cheaper than Claude Code with the --chrome flag (https://www.smooth.sh/images/comparison.gif). Happy to explain further how we’ve tested this and to answer any questions about it!
Instructions to install: https://docs.smooth.sh/cli. Plans and pricing: https://docs.smooth.sh/pricing.
It’s free to try, and we'd love to get feedback/ideas if you give it a go :)
We’d love to hear what you think, especially if you’ve tried using browsers with AI agents. Happy to answer questions, dig into tradeoffs, or explain any part of the design and implementation!
{kind=link}