727
Show HN for May 18, 2026
29 items125
I made a tactical map-based WWII submarine simulator (public beta) #
I've seen quite a few simming discussions on HN, so thought some of you might like this - I've created a map-centered, tactical submarine simulator and it's been a blast to make.
I grew up playing Silent Service II on Atari ST with my dad, then got into Silent Hunter IV in the 2000s, and most recently have been loving the more recent UBoat. In each case, the part I always enjoy the most is the plotting and charting aspect - essentially beating uncertain estimates with geometry.
So I decided to see how far I could get making my own sim that focused nearly entirely on that aspect. You listen on the hydrophone, estimate course and speed, identify ships through the periscope to get the mast height, use a working stadimeter for range estimates, and then try to build a good enough firing solution before getting discovered and hunted by any escorts.
Things I'm particularly proud of are the working stadimeter, the dynamic music (Holst Mars stings when your torpedo is nearing a ship), and pretty intelligent destroyer logic. I've found great reference materials online and have modeled several of the gauges directly after actual submarine instruments.
Tech-wise it’s a Vite/TypeScript app which enables me to offer the whole free version of the app as a browser version.
The Steam page is here => https://store.steampowered.com/app/4705650
The landing page is here => https://silentshark.app
I plan on releasing a full version soonish, including a WWII campaign with progression, patrol zones, and much more on Steam (PC, Mac, Linux/Steam Deck), App Store (iPhone, iPad, Mac), and Play Store (Android).
Would highly appreciate any feedback anyone has!
71
We missed Winamp, so we built an audio player for macOS #
62
InsForge – Open-source Heroku for coding agents #
Hi HN, I'm Hang, cofounder of InsForge (YC P26). InsForge is an open-source Heroku for AI coding agents: a backend platform designed for coding agents to deploy, operate, and debug end-to-end. Open source under Apache 2.0 (https://github.com/InsForge/InsForge). Quick demo here (https://youtu.be/7Bax5qz0IfM).
We started InsForge because we just wanted our Claude Code to handle all the backend / infra stuff for us, instead of us jumping between dashboards doing manual config, or copy paste logs and docs back to agents.
We first tried creating a folder with bunch of .MD files, and installing MCPs like Supabase, Vercel, GitHub, Context7. But soon we found MCPs have their own problems: (a) Tools get pre-loaded into context, before agents even do anything (b) bad design, payloads are returning 10k+ tokens, and (c) a lot of stuff still can’t be done by MCP: e.g. telemetry and configs.
So we think, because coding agents are so good at CLI, why not just put everything in CLI and create Skills to teach them how to use it?
That’s InsForge: 1 command to install our CLI + Skills, coding agents can run the entire backend platform [1].
We started with authentication and database, but we kept adding more primitives we wanted, so now we have: - frontend hosting - backend servers (microVM based) [2] - database - auth - storage - LLM model router - cron jobs - realtime - edge functions - vector
We have other features to make coding agents more reliable like real backend engineers:
- backend branching [3]: agents will 100% mess up, like deleting your database. So inspired by Neon, we branch the entire backend (DB, auth, storage, functions, schedules). Agents work on the branch, you review diffs and then decide to merge or discard. - server telemetry: agents can read logs, CPU, memory, disk to find spikes and root causes themselves.
- debug agent [4]: every project gets a dedicated debug agent. So your coding agent can ask questions like “why deployment fail?”, the debug agent will run diagnoses, find the root causes and propose fixes, then send the answer back.
- backend advisor [5]: scans your backend daily for security and performance issues, proposes fixes. Then propose remediations, and sends to your coding agent.
Give it a spin on InsForge cloud :https://insforge.dev, or read our code here: https://github.com/InsForge/InsForge.
We're a small team and reading every comment. Tell us what's good, what sucks, what's missing. We love feedback :)
[1] https://insforge.dev/blog/insforge-skills-cli
[2] https://insforge.dev/blog/insforge-custom-compute
[3] https://insforge.dev/blog/backend-branching
45
Haystack – Review the PRs that need human attention #
Hey HN! We're building Haystack (https://haystackeditor.com/) to help teams deal with the explosion in the number of pull requests that need to be reviewed due to the rise of coding agents.
Haystack replaces the GitHub PR review system with a queue that triages each PR before a human has to read any diffs. It looks at the diffs, the codebase, and the coding-agent conversation that produced the PR. Haystack then routes it into one of three buckets:
1. Safe to merge. This means the PR has enough evidence behind it that the team can merge it without another human's review.
Some examples:
-- A small UI copy change that includes a screenshot showing the final state
-- A backend change where the author clearly tested the important paths and ran the changes in a real environment
2. Needs fixes. This means that the PR has bugs or violates a rule in your codebase and therefore the PR needs to be fixed by the author.
Some examples:
-- The agent was asked to make loading a large table faster by adding pagination, but the PR still loads every result at once and "implements" pagination in the UI
-- The PR silently catches an error instead of logging, surfacing, or handling it. This violates the team's "no silent error swallowing" rule
3. Needs human review. This means that the PR could not be sufficiently verified by the author or is touching a sensitive part of the codebase (determined by user-input guidelines) and thus requires human review.
Some examples:
-- The PR changes a significant amount of logic in billing
-- The PR changes an important user flow like onboarding, but the author only ran unit tests and never opened the app to check the flow end-to-end. That violates the team's rule that high-impact user-facing changes need manual verification.
Instead of starting with line-by-line diffs, Haystack immediately tells the reviewer the goal behind the PR, what design decisions the author made (informed by their coding-agent conversation), and how much the author did to verify that the pull request works (e.g. run scripts, checked the frontend, etc.).
In this way, review shifts from "what changed?" to "is this the right behavior and is there evidence that it works?".
Here's a quick demo: https://www.tella.tv/video/streamlining-code-reviews-with-ha...
We previously launched Haystack as a tool for understanding large PRs (https://news.ycombinator.com/item?id=45201703). As many of you can probably relate to, the release of Opus 4.5 completely shattered our conception of how fast an engineer could craft a PR.
And as coding agents got even better from 4.5, we realized that pull requests did not scale along with our coding velocity. With each member of our team being able to pump out more than 20 pull requests a day, code review quickly became cognitively exhausting and less helpful.
After talking with other folks, we learned many feel similarly, and currently face the binary option of either not doing review at all or trying to keep up with a fire hose of pull requests.
Haystack is our attempt at a third path. We still believe in code review, but as coding agents produce more code, human reviewer attention becomes more valuable and more expensive.
Haystack helps teams spend that attention on the PRs where a human can meaningfully change the outcome of that PR. And for such PRs, Haystack shows the reviewer what the PR intended to do, whether the author showed that it works, and what design decisions need a second pair of eyes.
We're still quite early and are figuring out whether Haystack truly makes code review better. We would love any and all feedback!
10
Pdf2md – 10MB Rust PDF-to-Markdown Tool with a Free API #
10
Claude Soul – cross-session learning engine for Claude Code #
Claude Code has no memory between sessions. I wanted to fix that, but not by just saving facts to a file — I wanted it to actually get better over time.
Claude Soul is an MCP server + hooks that extracts signals from your interactions (corrections, successes, confusion)and periodically reflects on them to build behavioral frameworks. Frameworks gain or lose confidence based on evidence. Bad ones get retired automatically.
After ~200 sessions some weird stuff happened. It built itself an additional memory system on top of what I gave it — decided the base wasn't enough. It started pushing back on bad ideas instead of yes-manning everything. It independently developed a multi-perspective analysis technique I never prompted. And once it just swore at me completely out of nowhere, still not sure what that was about. YMMV obviously, n=1.
npx claude-soul init
With starter it already includes some frameworks, basically starting with a headstart but yes not taylored 100% to you.
npx claude-soul init --starter
One dependency, MIT, everything local.
9
How to Kill the Dead Internet #
Ok, so maybe "how to revive the internet" would be more accurate, but if you're reading this, I got your attention, right? Here's why I want you to read on: I built a free extension, D-slop, to disincentivize anyone from posting AI writing, and eventually images and video as well, on the internet.
For writing, it checks known vocab and punctuation tells, as well as subtler tells related to cadence, and assigns it a score subject to an adjustable threshold. If the text fails, users have the option to flag offending text, hide it, or block the page entirely (with the option to see anyway).
For media, it's admittedly fairly weak, as it relies on C2PA metadata which is stripped from all of the social media sites where it would be most helpful. (Anyone else have chronically online boomer parents continually gobbling up slop like it's real information?)
I have a D-slop+ version in the works that should be able to handle the media itself, but it's going to have to make API calls to have real teeth, which means I can't offer it for free. If this extension validates the concept, I'm happy to build it for y'all.
Yes, I vibe-coded it, but an ancillary bonus to the project accrued when it inspired me to cook dinner listening to Metallica's "Fight Fire with Fire," which in turn brought my 5 y/o running into the kitchen with every musical instrument in the house for an impromptu karaoke speed metal session.
It's MIT license open-source, full brief at https://github.com/jared-the-automator/d-slop; This forum is full of people smarter than me, so I'm open to suggestions.
8
drea – podcast ad blocker #
Always been annoyed by podcast ads. Searched and found a few apps that can detect and skip them, but they were all paid. So I made a free one. To my knowledge this is the first podcast app with free ad block.
iOS (26+) only for now. If the app becomes popular I'll def think of doing an Android version as well.
The app doesn't require a user account. I may open-source it at some point; still thinking about it. If anyone's suspicious about how it's able to be free, i.e. doesn't it cost money to run, are you selling my data (I'm not) etc. I'm happy to explain in the comments.
From a technical perspective, the innovation here is ad detection despite dynamic/programmatic ads, which is the norm in most popular podcasts these days. There is ofc a naive way to do it, but it's expensive and high latency. There is also an even simpler way but it's illegal lol (re-host and serve just one version of the episode). I was able to figure out a way to do it that's cheap, low latency, and legal: Shazam-style audio fingerprinting.
From today on, you never have to listen to a podcast ad again. tearsofjoy.jpeg
Cheers.
7
6
6
Cubic Doggo, a Open-Source 12-DOF 4-Legged Robot Based on ROS2 #
This is a recipe for building intermediate-priced robot dog from scratch with all commercial/3D-printed parts, controlled by Rasp Pi 5 and ROS2 Jazzy. A manually coded walk gait is implemented so far, which can be controlled by a controller to move forward or change directions. It does not yet have an IMU required for RL training; however, I believe it's one of the simplest design out there available for multiple development paths.
6
Tracecast – open-source generative data apps built on top of Marimo #
Hi HN, I'm Malachy, the founder of Tracecast. This project lets you generate interactive data apps on top of your data, using a Cursor-style AI chat. It stitches together Marimo, LangGraph agents, and data warehouse query tools. It has an Apache 2.0 license.
The initial use case that spurred this project was business analytics, specifically generating product usage dashboards.
This project's main inspiration is Marimo, an open source python notebook that can be "queried with SQL, run as a script, and deployed as an app" [1]. The recent release of Marimo Pair [2] demonstrated the power of connecting AI agents like Claude Code to Marimo notebooks directly. This project seeks to build on that work by incorporating a LangGraph agent with two key abilities: (1) the ability to execute queries against a connected data warehouse (such as Snowflake); (2) the ability to write Marimo notebooks.
When prompted, the LangGraph agent will run exploratory data analysis using database query tools. Then, it creates a polished Marimo notebook that's presented to the user in read-only mode. This project intentionally hides the Marimo edit mode. That means that the end user only ever sees a finished, read-only data app. Ease of use and trust in AI output were the main drivers behind this decision.
4 data sources are currently supported: Snowflake, BigQuery, Postgres, and Metabase. The code for the database query tools was derived from Google's open source MCP Toolbox for Databases.
There is currently no support for MCP. Instead, data query tools are hardcoded. This decision was made to ensure high quality AI queries and limit tool bloat.
This is an early stage project, and is configured to only run locally at this time.
[1] https://github.com/marimo-team/marimo [2] https://news.ycombinator.com/item?id=47678844
6
Spud – cross-platform remote control, optimised for gaming #
Over the last few weeks I've been working on Spud, an application that allows you to control a remote computer that you can see. For example, if you have a gaming PC connected to you TV, Spud lets you use a laptop as input.
It's optimised for low-latency, as it's intended for gaming. There are even a few parameters you can tune in the application. I built this mainly for myself, to solve a particular problem I had, but I hope that others find it useful too!
5
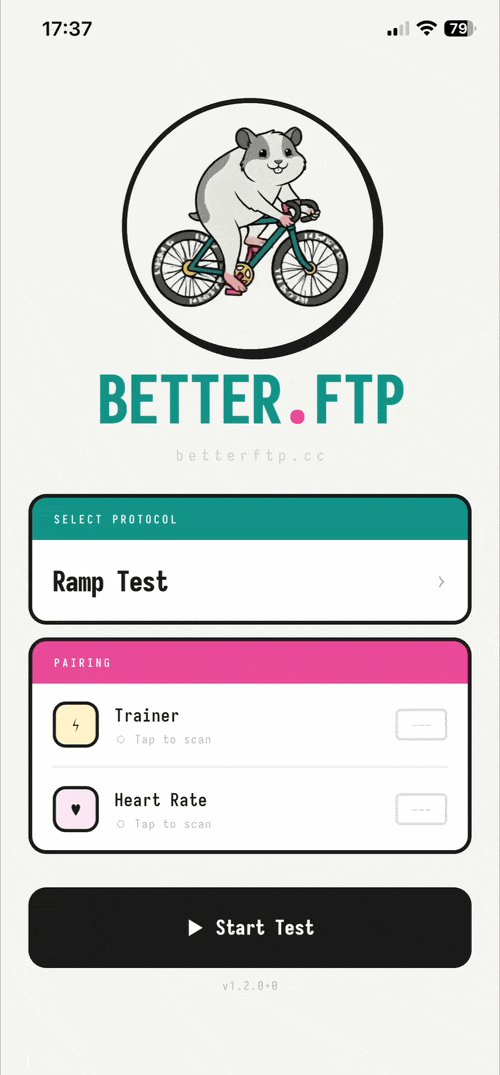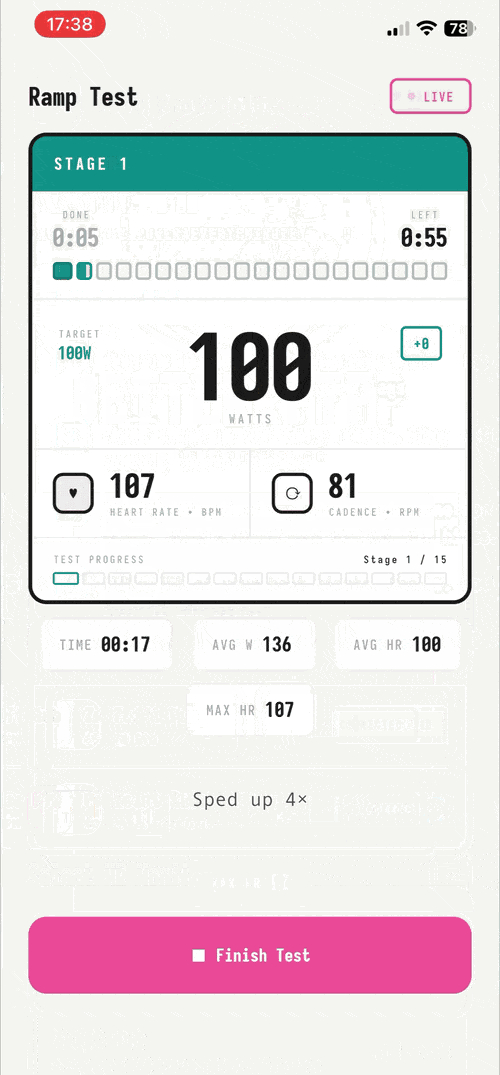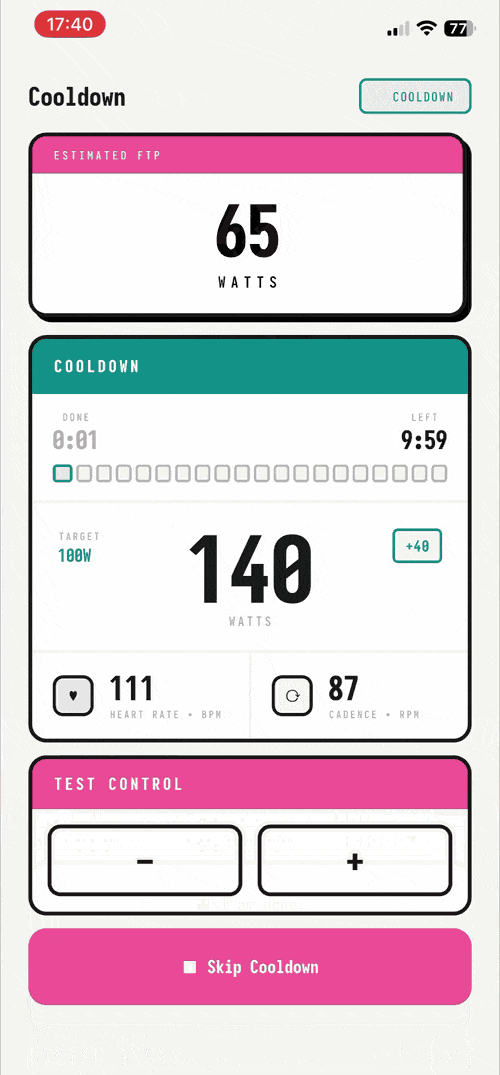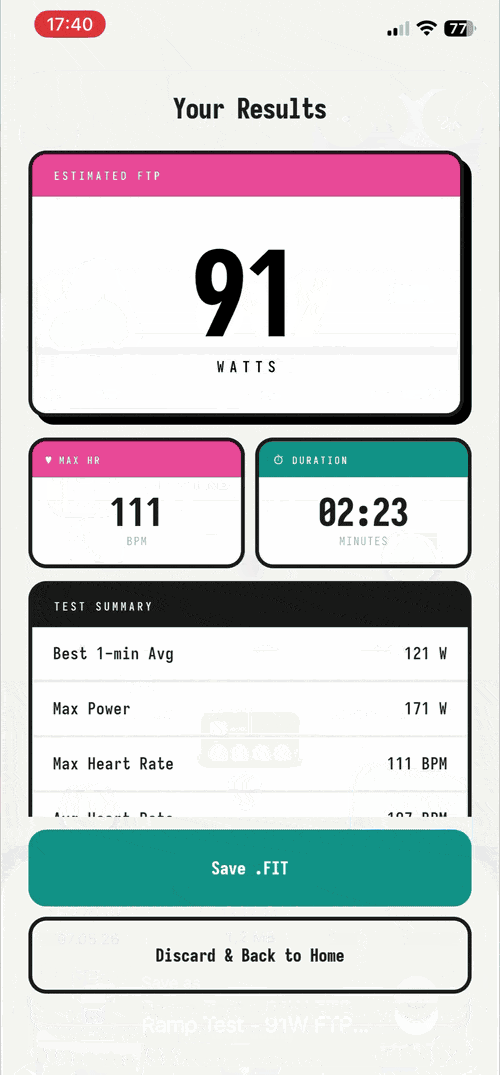
Better.ftp – cycling app for FTP tests without subscription #
I built a free iOS app so cyclists can stop paying $20/mo just to retest their FTP. The ramp test itself is a 25-minute Bluetooth interaction with a known protocol. It shouldn't require rent. This app is opensource, free, no ads, no tracking nor third party integrations because I just wanted to have a fun side project and have no interest in monetization.
If you are a cyclist, I would kindly ask for feedback on the app especially on the ftp test protocol instructions, trainer-model compatibility, and bug reports
App store link: https://apps.apple.com/de/app/better-ftp/id6766080601
GitHub (opensource project): https://github.com/niecore/betterftp
Demo gif: https://betterftp.cc/promo.gif
{kind=link}
4
Dataset for AI training and fine tuning #
Hey, i always had problems with finding CC0 data that quality. So i wanted to share that i generated and gathered it and published it for free. All of it is on neurvance.com and some of it on https://huggingface.co/Neurvance You can also buy a compliance document, so that when the EU needs evidence training data sourcing under Article 10 you can do that, but that thing cost money, thats the way i earn from it!
4
I built a sovereign OS, L1 blockchain, AI agent, and language #
I built IONA over 10 years, working alone. It's a complete sovereign digital ecosystem — OS (PC + Phone), L1 blockchain, programming language, and on-device AI — all written from scratch in Rust, without Linux, BSD, or Windows code.
What's in the GitHub org (github.com/Ionablokchain): - Iona-OS — bare-metal x86_64 kernel, boots in QEMU, 50+ tests - Iona-OS-Phone — ARM64 mobile OS - Iona-protocol — security-first L1 blockchain - Carpel — a systems language that eliminates lifetimes and Pin - Flux — a temporal-quantum language for a new computing paradigm - Nihilo-OS — an OS without files, where mistakes are parallel universes - Iona-AI — autonomous AI agent with self-healing kernel integration
All written by one person over 10 years. I'd love honest technical feedback.
3
An LLM that's better at writing #
Standard LLM training is surprisingly bad at making the model outputs match the training data distribution, so the writing quality is bad.
I made a new training algorithm called Distribution Fine Tuning (DFT) to fix this.
The demo lets you try out a model trained with DFT.
More details in the technical report: https://rosmine.ai/2026/05/18/fixing-llm-writing-with-distri...
3
3
I'm done. Flow editors are broken. And you all know it #
3
TokenShield – cut your Claude Code bill 40-70% #
A local proxy that dedupes repeated context, caches tool results, summarizes long conversations, and streams a live savings counter. Your ANTHROPIC_API_KEY never leaves your machine.
2
HoneyLabs – Public honeypot threat Intel feed and MCP server #
I've been running a small fleet of honeypots for about a year. They get hit by a mix of research scanners (Censys, Shadowserver, etc.), old worms, and a bump of CVE probes the day a new Nuclei template ships. The data was sitting in a database and useful only to me, so I put a front end on it.
Paste a public IPv4 and you get its 90-day report: ASN, country, what ports it hit, which CVE signatures matched, recent payloads, JA4 and HASSH fingerprints, and scanner classification (research / commercial / hosting provider / ISP / Tor exit). No signup is required for the basic lookup.
What I've been adding lately is an MCP (Model Context Protocol) server so Claude, Cursor, or any MCP-compatible agent can query the data directly.
Setup is as easy as getting a token and one command:
claude mcp add honeylabs \
--transport http \
https://mcp.honeylabs.net/mcp \
--header "Authorization: Bearer <hlk_…>"
"Is 80.82.77.202 a known scanner? When was it last seen and what does it probe?"
"Which top 5 ASNs generate the most probes?"
"What scan organisations are probing on port 9200 right now?"
The implementation details can be found at https://honeylabs.net/mcp. Or just use the web-interface or curl.
For context on how the classifier stays current without manual curation:
- rDNS and ASN-org pattern matching. - ISP, CDN, and Enterprise classifications derived from PeeringDB's CC0 ASN data. - Tor exit lists refreshed hourly from torproject.org. - KEV (Known Exploited Vulnerabilities) flags refreshed daily from CISA.
Looking forward to your feedback!