160
macOS menu bar app to track Claude usage in real time #
I built a macOS menu bar app to track Claude usage in real time via API after hitting limits mid-flow too often.
Signed and notarised by Apple. Open source.
Signed and notarised by Apple. Open source.
What it does:
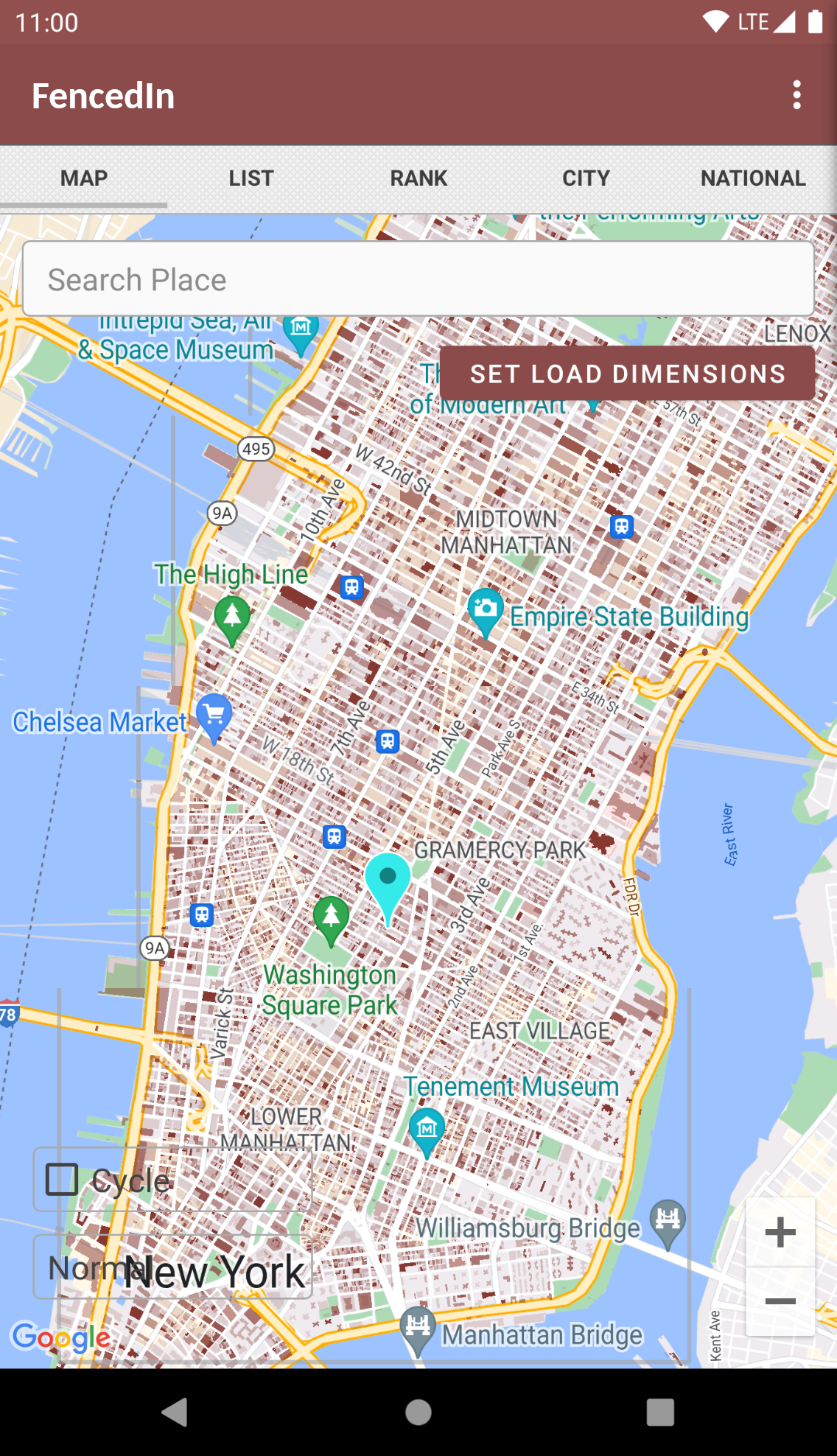
- Allows you to load a custom perimeter anywhere on the geographic map (180° E and W longitude and 90° N and S latitude), to cover area any area of interest
- Chat rooms get loaded within the perimeter
- You can chat with people within the perimeter
I developed a mobile app that uses an advanced geofence-based networking system from 2013 to 2019. My goal was to connect uses within polygon geofences anywhere in the world. The app is capable of loading millions of polygon geofences anywhere in the world.
https://enterpriseandroidfoundation.com/assets/images/other/...
But people didn't really have a need for this. So after failing, I spent the next 6 years trying to ideas to use FencedIn for. I tried a location-based video app and a place-based app that had multiple features. Nothing worked, but now I'm almost finished developing ChatLocal, an app that allows you to load a perimeter anywhere on the geographic map, which loads chat rooms.
The tech stack is 100% Java (low-level mostly). I have a backend, commons library and an Android app. Java was the natural choice back in 2013. However, I still wouldn't choose anything else today. Java is the best for long-term large-scale projects. (I'm also using WildFly. PostgreSQL and a Linux server.)
This app is still not fully finished, but I think the impact on society might be tremendous.
The previous app to ChatLocal, LocalVideo, is fully up on the Google Play store and can be tested. It has 88% of the features of ChatLocal, including especially the perimeter-based loading system.
The feedback I'm mostly looking for is new ideas and concepts to add to this location-based social media app. And how strong of a value proposition does the app have for society.
- Optical flow warps previous hallucinations into the current frame
- Occlusion masking prevents ghosting and hallucination transfer when objects move
- Advanced parameters (layers, octaves, iterations) still work
- Works on GPU, CPU, and Apple Silicon
All code -> https://github.com/JoeAzar/pokerbench
* Groups all tabs from same domain. Makes it simple to kill all your Gmail tabs in one click (or keep just one).
* Groups all tabs playing audio. Toggle the sound for each one.
* Single text search for open tabs, bookmarks, and browsing history.
* Groups all tabs with new notifications (e.g. emails, likes, posts, replies, etc.)
* One click to kill all tabs (e.g. you're sharing screen in Zoom). A second click brings them all back.
I'm a solo web developer and I'm hoping to build an audience with my work. More at: https://buymeacoffee.com/kawaicheung
I have absolutely no clue how I got the idea, other than the fact that I grew up in the Orthodox Church and all my other coding projects have been faith-related (a terrible mobile app (1) and slightly broken Byzantine chant website (2) ). I'm a relatively new developer and I've been hungry for a project to build that people will actually use and share around, so I hoped this would fit the bill.
Sure enough, friends and family have been making it part of their daily routine. When priests AND my nonreligious college friends started sending me their results every day, I knew I had something. It was really exciting.
------
When the idea popped into my head, I started working on it right away. I created the project at 1AM and had a MVP/SLC version done a few hours later. That was a few weeks ago.
I am using SvelteKit, no external APIs, and SQLite for the database. It's hosted on an Ubuntu machine in my living room. Coding agents like Roo/Kilo Code assisted heavily in the development, but after I had already decided on the overall architecture and how I wanted things to work together.
The game is free, has no signup, and I’m not running any ads. I’m looking for any and all feedback, and especially suggestions for how I can make the game more interesting, fun, and/or educational.
Thank you HN!
I found Qiaogun's implementation (ADHD_Blink) for M5StickC Plus, and adapted it for the newer M5StickC Plus2 with some tweaks - simpler 50% duty cycle flash, configurable ramp-down, auto sleep, etc.
Honestly, I'm not sure if it actually works. I'll be trying it out myself to see. But the building process itself was quite fascinating.
I used Claude Code for the entire implementation - from reading the original codebase, to modifying the firmware, to flashing the device. There's something surreal about an AI having full control over a physical piece of hardware.
It made me wonder: in the future, could AI-connected devices dynamically rewrite their own firmware based on user needs? Imagine telling your device "make this button do X instead" and it just... does.
Original HN comment: https://news.ycombinator.com/item?id=38274782 Based on: https://github.com/Qiaogun/ADHD_Blink Hardware: M5StickC Plus2 (~$20)
Happy to hear thoughts, or if anyone has actually tried this LED trick.
Notion's native solution doesn't work:
Row-level filtering exists but it's view-only (contractors can't edit)
Column hiding doesn't exist
Guest sharing is read-only
So you either pay $15/mo per seat or duplicate databases (maintenance nightmare)
I built a permissions layer using Notion's OAuth API. It lets contractors see only specific rows and columns, edit data, all without expensive seats.
How it works:
Connect Notion via OAuth
Define roles: "Sales reps see only leads where owner = them, hide pricing column"
Contractors access a clean portal
They view/edit data in real-time (syncs every 5 minutes)
You pay $59/mo flat for unlimited users
The math:
5 contractors × $15/mo = $900/year wasted
20 contractors × $15/mo = $3,600/year wasted
50 contractors × $15/mo = $9,000/year wasted
With this: all of them = $59/mo flat.
Technical:
Frontend: React + TypeScript
Backend: Supabase + PostgreSQL (RLS)
Auth: Notion OAuth 2.0
Current state: 50 beta testers. First 20 customers get $49/month locked-in (launching at $79 after January).
Limitations:
Only Notion databases (not pages)
5-minute sync (not instant)
Requires role definition
No team permissions yet (roadmap)
The ask: If this solves a problem you have, we'd love feedback. Are there permission use cases we're missing? What's your price sensitivity?
Free trial: notionportals.com
The backend is OpenAI-compatible (/v1/chat/completions), with usage-based pricing and no prompt/output retention by default (details on the site). The UI is meant for long-form character chats and interactive fiction, without needing a local frontend.
Docs (including a roleplay backend guide and a SillyTavern integration guide): https://abliteration.ai/docs
Would love feedback on missing RP features, UX rough edges, and what you would expect from a roleplay-first interface.
Under the hood it spins up a GitHub Codespace, installs Claude Code, and connects the iOS client to it securely. You can use a full terminal when needed, or a lightweight native UI for monitoring and interaction.
I built this because Claude Code is most useful when it has access to a persistent environment with plugins, tools, and real repos — and I wanted that flexibility away from my laptop.
GitHub gives personal users 120 free Codespaces hours/month, and Catnip automatically shuts down inactive instances.
Open source: https://github.com/wandb/catnip App Store: https://apps.apple.com/us/app/w-b-catnip/id6755161660
Happy to answer questions or hear feedback.
Structural SSOT is achievable only when a language provides definition-time hooks and runtime introspection. Macros/codegen (before definition) and reflection (after definition) are insufficient. These requirements are derived, not chosen: because structural facts are fixed at definition, derivation must occur at definition time and be introspectable to verify DOF = 1.
Would appreciate review, critique, or independent checking of the Lean scripts.
I built this to solve my own task paralysis problem. The app only shows one next task instead of a full list.
It’s open source and still very early. Feedback welcome.
I’ve been working on Flowscape, a 2D canvas engine focused on building interactive editors and visual tools. It provides low-level control over scenes, nodes, and interactions without enforcing a specific UI or workflow.
The goal is to give developers a flexible foundation for custom editors, diagrams, and canvas-based interfaces. I’d love feedback on the API design, architecture, and real-world use cases.
Demo: https://flowscape-ui.github.io/core-sdk/?path=/story/interac... GitHub: https://github.com/Flowscape-UI/core-sdk
Thresholds:
France/Belgium: 34 days/year Germany: 183 days/year
Most companies track this manually or not at all, creating audit and penalty risk.
Key Features
For Employees:
One-click daily declarations via automated email prompts with real-time threshold tracking
For HR/Compliance:
Real-time compliance dashboard with alerts across the entire workforce
Complete audit trail for regulatory inspections
Links
Live: https://remotedays.app
Demo: https://demo.remotedays.app
Built with security and GDPR compliance as core requirements. Currently seeking feedback and open to customization or developing similar compliance solutions for specific organizational needs.
Questions and feedback welcome.
- Audio >29s is chunked with ffmpeg - Audio chunks and prompts are submitted in parallel to the playground via Playwright - Web UI for storing tracks and re-editing previous outputs
Demo video: https://github.com/user-attachments/assets/d5d3b53d-6ac9-40f...
TierHive is my attempt to make 128MB VPS great again :)
It's a NAT VPS (KVM) platform with true hourly billing. Spin up a server, use it for 3 hours, delete it, pay for 3 hours. No monthly commitments, no minimums beyond a $5 top-up.
The tradeoff is NAT (no dedicated IPv4), but I've tried to make that less painful:
- Every account gets a /24 private subnet with full DHCP management. - Every server gets auto ssh port forwarding and a few TCP/UDP ports - Built-in HAProxy with Let's Encrypt SSL, load balancing, and auto-failover - WireGuard mesh between locations (Canada, Germany, UK currently) - PXE/iPXE boot support for custom installs - Email relay with DKIM/SPF - Recipe system for one-click deploys
Still in alpha. Small team, rough edges, but I've been running my own stuff on it for months. Would love feedback — especially on whether the NAT tradeoff kills it for your use cases, or what's missing. (IPv6 is coming) https://tierhive.com
Key features: - Works on any AI platform (ChatGPT, Claude, Gemini, Perplexity) - XML/JSON output modes for structured prompts - Privacy-first: prompts enhanced but not stored - Free tier: 3 enhancements/day
Available for Chrome and Firefox. Would love feedback from the HN community!
I'm Daniel, a solo dev from Italy. I built LaraPlugins.io to solve a specific pain point I kept hitting: finding a Laravel package, installing it, and only realizing weeks later that it was abandoned or incompatible with the latest PHP version.
It’s a directory that assigns an automated "Health Score" to packages based on maintenance, testing, and community signals (not just popularity).
The Stack:
Backend: Laravel running on Octane (FrankenPhp) for high performance.
Admin: Filament PHP (which has been a joy to work with).
Queues: Heavy use of Redis queues to ingest stats from Packagist/GitHub in the background and also for the heavy cache usage i applied.
Cloudflare: Everything is cached in cloudflare after the first load so even big traffic should not impact the server machine directly.
Workers: Managed via Laravel Horizon running in a single Docker container.
Frontend: Blade templates + Tailwind CSS.
It categorizes emerging AI platforms and educational content to help both beginners and experienced builders find high-quality tools and learning paths in one place. Features include:
• Curated collection of AI tools across categories • Tutorials, guides, and explainers for practical usage • Featured projects and community contributions • Search and tagging for quick discovery
Would love to hear what the HN community thinks — feedback, ideas, or areas to improve are all welcome!
All elements have an experiment animation such as a flame test, radioactivity or alkaline water explosion. The first two rows have real world pictures related to the elements, which take a bit to find and describe. I don't have any background in chemistry but have hopefully avoided basic mistakes.
I tried to keep the text educational but accessible - I imagine the target audience being kids like my own, or a younger me. Curious learners but young, so the text occasionally i.e. mentions nutrition or clarifies what "synthetic" means.
On the technical side, I have minimal Web experience and don't find the visual/UI side of development very fun so I wanted to build this without any JS frameworks or extensive use of JS. The backend is written in Go and the frontend interactivity is mostly done with HTMX and unsophisticated JS. The experiment visualizations for elements like lead and quicksilver are SVG shapes to which simple animation steps are applied.
Would love to hear any thoughts on the general approach, the element visualizations and any other points from HN readers. In particular I would welcome ideas about the transuranium elements, I have essentially the same Geiger visualization for many, and a silly particle beam collision for others because I wasn't able to come across any accessible differences between these elements.
Upload CV → paste job → get personalized proposal in seconds. It analyzes job quality and flags problematic clients too.
I’m Robert, the developer behind It Happened Again (https://ithappenedagain.fyi).
Let’s start with an example: "AWS us-east-1 outage": A structured timeline of every outage since 2017, with sources, verification, and a "live days since last incident" counter.
The Problem
I built this after realizing I had personally argued about the same repeating topics like SaaS outages, breaking changes, and AI claims multiple times, with no shared reference to point to.
Social media feeds are built on recency. They do not have any long-term memory. When a provider has its 5th outage of the year, that context is buried under new content. To stay updated, you have to constantly refresh, which generates high noise and low signal.
What it does
IHA lets you create a single, shared timeline for things that keep happening - outages, broken promises, policy reversals - and attach evidence each time they recur.
You can think of it like Imgur was for Reddit, but for context instead of images. You create a Record (the pattern) and add Occurrences (each time it happens) to provide chronological evidence.
Key Features
- Structured Timelines: A strict chronological record of recurring events (e.g., "Steam Deck on sale", "Feature X promised but not delivered"). - Active Monitoring: Subscribe to specific Records. Instead of refreshing a feed, you get notified (in-app or email digest) only when "it happens again." - Privacy First: No tracking pixels, no data selling. Analytics via anonymized Posthog (EU Cloud).
Weighted Verification (An Experiment)
We intentionally started with a simple, transparent scoring model (implemented in our Verification Service) so the community can ‘attack it’ and help us improve it. We don't use black-box AI to try to determine truth.
Current Weights (launch version):
- Moderators: 3x multiplier - Trusted Contributors: 2x multiplier - Account Age: up to +20% boost - Evidence Quality: Currently +5% per link. (Yes, we know this linear scaling is naive - we are specifically looking for feedback on better distinct-domain heuristics!)
Under the Hood
IHA was developed over the last 12 months using a Modular Monolith architecture to keep the codebase sane:
1. Stack: Next.js 15, Drizzle ORM, Postgres, Redis, BullMQ.
2. Service Layer: We use a Service Registry pattern to isolate business logic (like verification rules) from the web layer, ensuring the "truth logic" is testable.
3. Infrastructure: EU-based. Hetzner (App/DB), Posthog (Analytics), Backblaze B2 (Storage).
Common Questions
Wait, "AI" helped you build it, but does it "run it"?
No. LLMs are not used to verify submitted information. AI (Claude/Codex/Gemini) acted as a force multiplier to write the code, but the logic is deterministic and always reviewed by a human.
How do you prevent brigading or misinformation?
We use a two-tier moderation system (Local Moderators assigned by the Record's creator/owner, similar to subreddits, alongside Global Moderators’ oversight) and a "Trusted Contributor" reputation system to weight verification scores.
Why I built it
I started this as a way to stop re-litigating the same facts in comment threads - as much for myself as for everyone liking evidence-based data. The goal isn't to replace social networks, but to build the "memory layer" that they lack - effectively bringing OSINT-style tracking to everyday recurring events (and, hopefully, making it fun).
The app is live here: https://ithappenedagain.fyi
I’m specifically looking for feedback on how you would game or attack the verification model - assume bad actors and incentives.
Thanks!
Instead of every product/team reinventing avatar styles, SquareFaceIcon treats a face icon as a tiny, structured “packet”: - fixed square canvas - a small set of discrete layers (skin, hair, eyes, mouth, extras, background) - finite, enumerable options per layer (IDs instead of pixels)
That gives you: - *Deterministic avatars from a tiny config* – you can describe an avatar with a short JSON (or even a few bytes), then render it anywhere the “protocol” is implemented. No binary image assets needed. - *Consistent visual language* – all combinations obey the same square-face “grammar”, so a community, product, or game can have hundreds of unique avatars that still look like one family. - *Cheap to store and send* – configs can live in your DB/user table, be generated from a hash, or passed in URLs, then rendered on the client.
The hosted generator at squarefaceicon.top is one reference implementation: - 200+ pre-defined parts across multiple categories. - Pure HTML5/JS, runs fully in the browser, no sign-in and no server-side image processing. - Exports transparent PNGs in multiple sizes (64–512px) for Discord, forums, games, etc.
Why this might be useful: - Small apps or side projects get a drop-in avatar system without dealing with uploads, moderation, or external CDNs. - Communities can standardize on a simple avatar spec and still let users fully customize their look. - Devs can re-implement the renderer in any stack (Canvas/WebGL/SVG/native) as long as they respect the same part IDs and layout rules.
If folks are interested, happy to: - document the “protocol” more formally (schema for the avatar config) - publish a minimal open-source renderer - add an API for server-side generation
Feedback welcome on: - what you’d want from such a tiny avatar “protocol” (versioning? theming? accessories?) - whether you’d use this in a product, and what integrations you’d need (React/Vue components, game engines, etc.)
Over the weekend I felt nostalgic for classic anthology-style storytelling and wanted to see if I could create something new in that format. Rather than trying to imitate any specific show, I was interested in the broader idea of short speculative stories built around irony, choice, and unintended consequences.
I decided to experiment with AI as a storytelling tool. Going in, I expected the results to be fairly mediocre, but I was genuinely surprised by the output. Some of the stories — and even the generated images — were better than I anticipated and made me want to explore the idea further.
The result is Twisted Logic, a small choose-your-own-path anthology story generator. It can use Google’s Gemini models if you provide an API key, but I’ve also been working to make it function with free alternatives and allow people running local LLMs to point the project at their own models. By default it uses free generators and the browser’s built-in voice (which can be turned off).
The project is free to use and open source (https://github.com/anefiox/TwistedLogic). I mainly built it as a hobby experiment and a way to explore generative storytelling and interactive narrative design. If anybody wants some links to the some stories generated as ebups please let me know.
I’ve been fascinated by how Chatbot Arena gamified the ranking of LLMs, so I wanted to apply that same pairwise/Elo logic to visual design and aesthetics.
The idea is that while it’s hard to objectively rank a list of 50 things, it’s intuitive to choose the better option between two.
I just launched with a few categories, but the one you might find most interesting is the "Programming Language Logos" arena.
I’m curious to hear your thoughts on the mechanics or if you think this approach actually captures "taste" effectively.
Thanks for checking it out.
Why I built it: I often need to ship release artifacts for users across different OSes, and ISO compatibility gets tricky fast (Unicode filenames, large files, UNIX perms, and “what mounts cleanly where”). I wanted a single tool that lets me author one image with the right filesystem mix for cross-platform distribution.
What it does: Create new ISOs: start a new project → set volume/publisher identifiers → choose standards → drag & drop files/folders → build the image (with progress shown). Edit existing ISOs: open an ISO and add/replace/delete content, update properties/standards, then save/build the updated image.
Standards support (and you can master multiple standards into one ISO for compatibility): ISO9660 + Joliet (long/Unicode filenames) UDF 2.60 (e.g. files > 4GB) Rock Ridge 1.09 (UNIX permissions/attributes)
Feedback/questions I’d love help with: For cross-platform distribution, what compatibility edge cases should I test (deep paths, Unicode normalization, mixed-standard mounting behavior, large trees, etc.) Would a Linux version be useful (native GUI), or are existing Linux toolchains (xorriso/mkisofs/etc.) already “good enough” for most people?
Happy to answer questions.
Instead of an interpreter or JIT, Copapy builds a computation graph by tracing Python code and uses a copy-and-patch compiler to assemble machine code from precompiled templates, patched at compile time. The result is static native code with no GC, no syscalls, and no memory allocations at runtime. Once compiled, execution is fully predictable, and instruction counts and latency can be reasoned about ahead of execution. It also supports automatic differentiation, which is useful for control, optimization, and estimation workloads.
Copapy treats Python as a frontend, not a runtime. During tracing, standard Python code is executed, allowing to benefit from Python's expressiveness and tooling.
The copy-and-patch compiler makes porting to new architectures straightforward as long as a C compiler is available. x86_64 as well as 32- and 64-bit ARM are already supported. Copapy comes as small Python package with minimal dependencies, and does not require a cross-compilation toolchain since the package ships with precompiled stencils.
The current focus is on robotics, aerospace, embedded systems, and control systems in general.
This project is early but already usable and easy to try out. If anyone is interested in integrating Copapy into commercial hardware products, or adopting it for open source projects, I'd love to hear about real use cases and constraints.
THE PROBLEM: GLOBAL CONTEXT COLLISION
The standard way to switch configurations in GCP is "gcloud config configurations activate ". However, this changes the GLOBAL state of the SDK. If you have several terminal tabs open---perhaps one for Production logs and another for a Staging deploy---switching the configuration in one tab silently changes it for all others. It's too easy to accidentally run a destructive command in the wrong environment.
THE SOLUTION: SESSION-SCOPED SWITCHING
gsw leverages the CLOUDSDK_ACTIVE_CONFIG_NAME environment variable to isolate configuration changes to the CURRENT shell session only.
gsw : Switches the current tab (Safe by default). gsw -g : Switches globally when you actually need it. WHY NOT JUST USE DIRENV OR ALIASES?
vs direnv: direnv is great for directory-specific settings. gsw is for ad-hoc, manual switching regardless of where you are in your filesystem. vs aliases: Managing dozens of projects with aliases gets messy. gsw gives you dynamic tab-completion based on your actual gcloud configurations. KEY FEATURES
KISS approach: No binaries, no heavy dependencies. Just a few shell functions that wrap environment variables. Developer Experience: Fast, interactive tab-completion for both Bash and Zsh. Safety First: Running gsw without arguments lists your configs and highlights who you are and what is active. GET STARTED
It is just one shell file. You can install it manually or via plugin managers to keep it clean.
GitHub: https://github.com/sakebook/gsw
I'd love to hear how you manage your cloud contexts or any feedback on making this even safer!
Hi HN,
I built Wozz, an open-source CLI and GitHub Action to catch expensive Kubernetes configs before they merge.
The Motivation I noticed that most cloud cost tools (like Kubecost) only show you the bill 30 days later. By then, the over-provisioned sidecar or massive Java heap is already in production. I wanted something that acts like a unit test for resource requests blocking fat finger mistakes in the PR rather than waiting for the bill.
How it works Wozz runs in two modes:
In CI/CD (The Linter): It parses the git diff of your manifests (deployment.yaml, etc.), calculates the cost delta (requests × replicas), and posts a comment if the change exceeds a threshold (e.g., +$50/mo). It also checks HorizontalPodAutoscaler limits to flag worst-case scaling risks.
Locally (The Auditor): It scans your current kubecontext to compare reserved requests vs. actual live usage (kubectl top). This helps find the "Sleep Insurance" gap—where devs request 4GB RAM just to be safe, but the app only uses 200MB.
Implementation Details
Stack: TypeScript/Node.js.
Math: Instead of querying AWS Cost APIs (which requires sensitive creds and is slow), it uses a configurable Blended Rate (e.g., $0.04/GB/hr) to estimate costs deterministically.
Privacy: It runs 100% locally or in your runner. No manifests or secrets are sent to any external server.
Repo https://github.com/WozzHQ/wozz
Feedback I’m currently using a static Blended Rate for the cost math to keep the tool fast and stateless. I’m curious if this approximation is accurate enough for your team's guardrails, or if you strictly require real-time Spot Instance pricing to trust a tool like this?
This uses the Vision framework to look at stuff like facial expressions, focus, picture quality. It also has keyboard shortcuts that make it really fast to review, so I managed to delete about 150 GB of photos by mostly pressing "return" over and over again for a couple hours. (It has an autopilot mode, but even though I'd say it gets things right from my perspective about 90% of the time, I didn't trust it completely on my kid photos. Might be great though on particular albums that weren't especially important.)
Instead of filtering PRs, scanning commit logs, or asking engineers for updates:
- "What shipped last week?" - "Who's been working on the API?" - "Which PRs have been open longest?" - "Summarize this month's releases"
Plain English in, plain English out.
*How it works:*
Connect your repos via OAuth. We register webhooks. Every event gets normalized into a structured schema – commit message, PR description, author, timestamp, files changed.
The AI queries structured data, not raw text. PR descriptions and titles carry context that individual commits often miss.
*Automated reports:*
Don't want to ask? Schedule it.
Weekly or monthly summaries delivered to Slack or email. Forward to stakeholders or let it run on autopilot.
*Other features:* - Slack bot: Ask from where you already work - Public changelog: yourcompany.gitmore.io/changelog - Contributor leaderboard
*Security:*
Metadata only. We store commit messages, PR titles, descriptions, timestamps, authors.
We never access source code, diffs, or file contents.
- Token encryption: Fernet (HMAC-SHA256 + AES-128-CBC) - Webhook verification: HMAC-SHA256 - 2FA support
Verify yourself: check webhook settings after connecting.
Free for 1 repo: https://gitmore.io
{kind=link}